

![]()
![]()
Datasette 插件,为您的 SQLite 数据库提供自动的 GraphQL API
阅读更多关于此项目的信息: 使用新的 datasette-graphql 插件在 Datasette 中使用 GraphQL
在线试用演示,请访问 datasette-graphql-demo.datasette.io/graphql
在与 Datasette 相同的环境中安装此插件。
$ datasette install datasette-graphql
默认情况下,此插件在 /graphql 添加 GraphQL API。您可以使用 path 插件设置配置不同的路径,例如将此添加到 metadata.json 中
{
"plugins": {
"datasette-graphql": {
"path": "/-/graphql"
}
}
}这将把 GraphQL API 设置为位于 /-/graphql。
此插件将 /graphql 设置为第一个附加数据库的 GraphQL 端点。
如果您有多个附加数据库,每个数据库都将在 /graphql/name_of_database 拥有自己的端点。
自动生成的 GraphQL schema 可在 /graphql/name_of_database.graphql 获取 - 这里是一个示例。
可以像这样查询单个表(和 SQL 视图)
{
repos {
nodes {
id
full_name
description_
}
}
}在此示例查询中,底层数据库表名为 repos,其列包括 id、full_name 和 description。由于 description 是保留字,查询需要使用 description_。
如果您只想获取单条记录 - 例如,如果您想通过主键获取行 - 您可以使用 tablename_row 字段
{
repos_row(id: 107914493) {
id
full_name
description_
}
}tablename_row 字段接受主键列(或多个列)作为参数。它还支持与 tablename 字段相同的 filter:、search:、sort: 和 sort_desc: 参数,如下所述。
如果某个列是另一个表的外键,您可以使用嵌套查询来请求该外键指向的表中的列,如下所示
{
repos {
nodes {
id
full_name
owner {
id
login
}
}
}
}如果另一个表有一个外键指向您正在访问的表,您可以从该相关表中获取行。
考虑一个与 repos 相关的 users 表 - 一个 repo 有一个外键指向拥有该 repository 的用户。users 对象类型将有一个 repos_by_owner_list 字段,可用于访问这些相关的 repos
{
users(first: 1, search: "simonw") {
nodes {
name
repos_by_owner_list(first: 5) {
totalCount
nodes {
full_name
}
}
}
}
}您可以使用 filter: 参数过滤特定表返回的行。它接受一个 filter 对象,将列映射到操作。例如,要仅返回使用 Apache 2 许可且星标数超过 10 的 repositories
{
repos(filter: {license: {eq: "apache-2.0"}, stargazers_count: {gt: 10}}) {
nodes {
full_name
stargazers_count
license {
key
}
}
}
}有关更多操作,请参阅表过滤器示例,有关这些操作如何工作的详细信息,请参阅 Datasette 文档中的列过滤器参数。
这些相同的过滤器也可用于嵌套关系,如下所示
{
users_row(id: 9599) {
name
repos_by_owner_list(filter: {name: {startswith: "datasette-"}}) {
totalCount
nodes {
full_name
}
}
}
}当您要表达的内容过于复杂而无法使用 filter 表达式建模时,where: 参数可以作为 filter: 的替代。它接受一段 SQL 字符串片段,该片段将包含在 SQL 查询的 WHERE 子句中。
{
repos(where: "name='sqlite-utils' or name like 'datasette-%'") {
totalCount
nodes {
full_name
}
}
}您可以使用 sort: 或 sort_desc: 参数设置表结果的排序顺序。此参数的值应为您希望排序(或降序排序)的列的名称。
{
repos(sort_desc: stargazers_count) {
nodes {
full_name
stargazers_count
}
}
}默认情况下,将返回前 10 行。您可以使用 first: 参数控制此行为。
{
repos(first: 20) {
totalCount
pageInfo {
hasNextPage
endCursor
}
nodes {
full_name
stargazers_count
license {
key
}
}
}
}totalCount 字段返回与查询匹配的记录总数。
请求 pageInfo.endCursor 字段会为您提供请求下一页所需的值。您可以将其传递给 after: 参数来请求下一页。
{
repos(first: 20, after: "134874019") {
totalCount
pageInfo {
hasNextPage
endCursor
}
nodes {
full_name
stargazers_count
license {
key
}
}
}
}hasNextPage 字段告诉您是否还有更多记录。
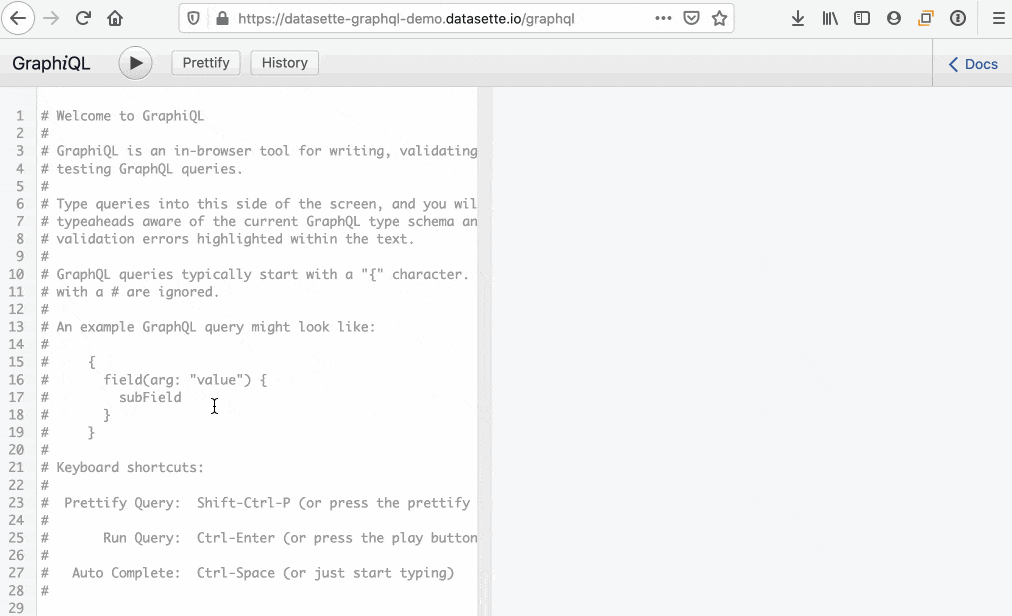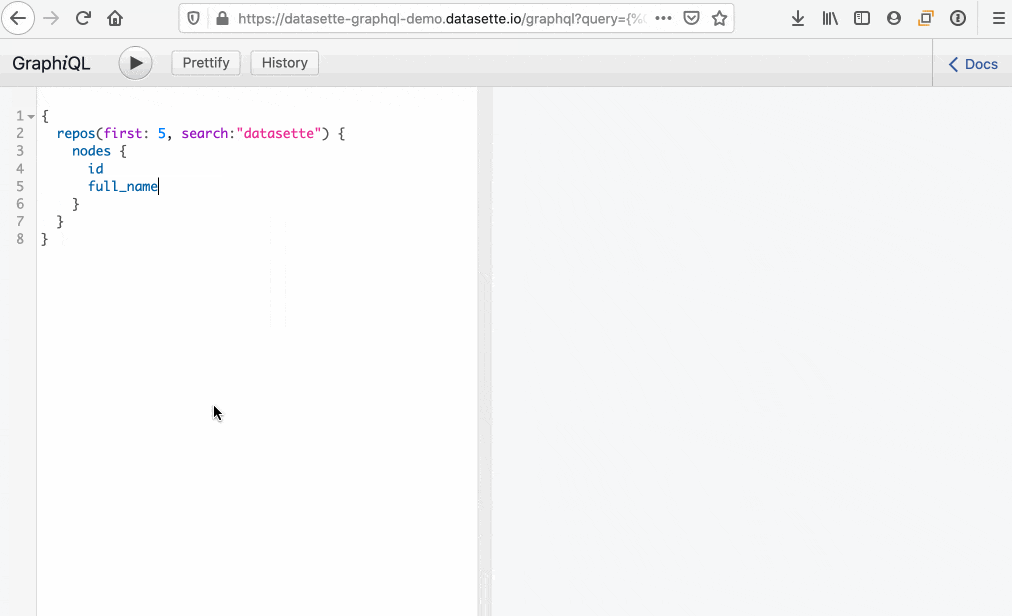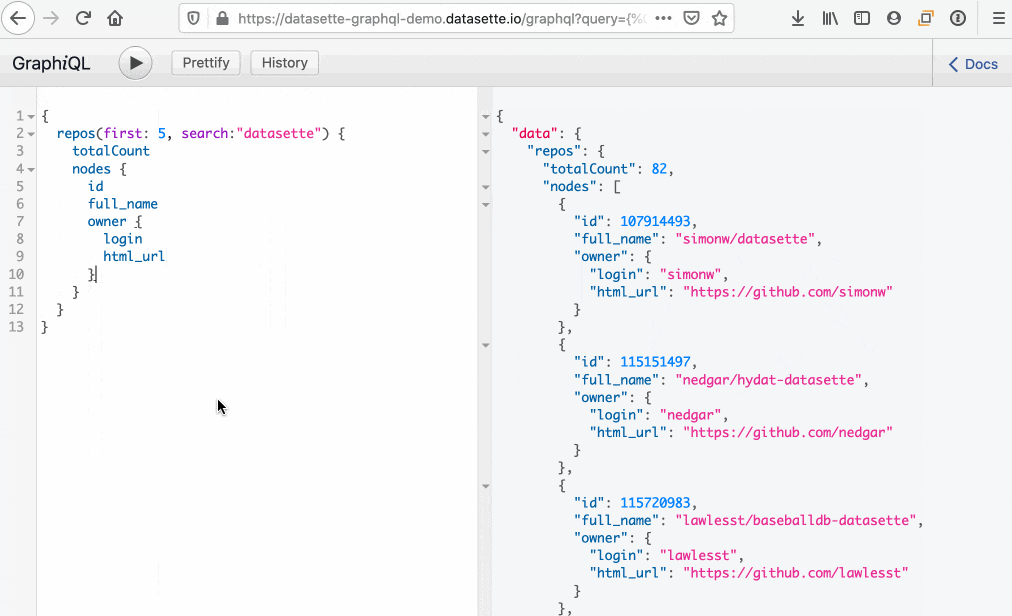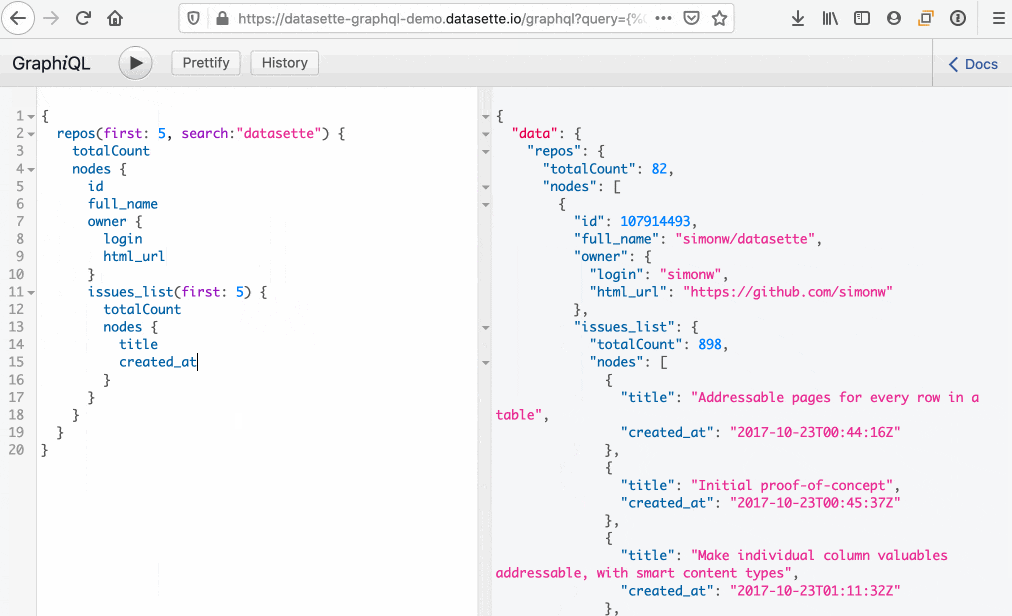
如果表已配置为使用 SQLite 全文搜索,您可以使用 search: 参数对其执行搜索
{
repos(search: "datasette") {
totalCount
pageInfo {
hasNextPage
endCursor
}
nodes {
full_name
description_
}
}
}可以使用 sqlite-utils Python 库和 CLI 工具向现有数据库表添加全文搜索。
如果您的表包含一个包含 JSON 编码数据的列,datasette-graphql 将使该列作为编码的 JSON 字符串可用。调用您的 API 的客户端需要将该字符串解析为 JSON 才能访问数据。
您可以通过配置该列作为 JSON 列处理,将数据作为嵌套结构返回。在 metadata.json 中的插件配置如下所示
{
"databases": {
"test": {
"tables": {
"repos": {
"plugins": {
"datasette-graphql": {
"json_columns": [
"tags"
]
}
}
}
}
}
}
}您的列和表的名称默认与其在 GraphQL 中的表示匹配。
如果您有使用 names_like_this 命名方式的表,为了与 GraphQL 和 JavaScript 约定保持一致,您可能希望在 GraphQL 中使用 namesLikeThis。
您可以在 metadata.json 中使用 "auto_camelcase" 插件配置设置开启自动 camelCase,如下所示
{
"plugins": {
"datasette-graphql": {
"auto_camelcase": true
}
}
}此插件遵循传递给 datasette 命令行工具的 --cors 选项。如果您传递 --cors,它将添加以下 CORS HTTP 头部,以允许在其他域上运行的 JavaScript 访问 GraphQL API
access-control-allow-headers: content-type
access-control-allow-method: POST
access-control-allow-origin: *
默认情况下,该插件实现了两个限制
- 执行组成 GraphQL 执行的所有底层 SQL 查询所花费的总时间不得超过 1000 毫秒(一秒)
- 由于嵌套的 GraphQL 字段而执行的 SQL 表查询总数不得超过 100
可以使用 num_queries_limit 和 time_limit_ms 插件配置设置来自定义这些限制,例如在 metadata.json 中
{
"plugins": {
"datasette-graphql": {
"num_queries_limit": 200,
"time_limit_ms": 5000
}
}
}将这些值设置为 0 将完全禁用限制检查。
该插件还提供了一个名为 graphql() 的 Jinja 模板函数。您可以在 Datasette 的自定义模板中使用该函数,如下所示
{% set users = graphql("""
{
users {
nodes {
name
points
score
}
}
}
""")["users"] %}
{% for user in users.nodes %}
<p>{{ user.name }} - points: {{ user.points }}, score = {{ user.score }}p>
{% endfor %}该函数针对生成的 schema 执行 GraphQL 查询并返回结果。您可以将这些结果分配给模板中的变量,然后遍历并显示它们。
默认情况下,查询将针对第一个附加数据库运行。您可以使用函数的第二个可选参数来指定不同的数据库 - 例如,要针对附加的 github.db 数据库运行,您可以这样做
{% set user = graphql("""
{
users_row(id:9599) {
name
login
avatar_url
}
}
""", "github")["users_row"] %}
<h1>Hello, {{ user.name }}h1>您可以通过将GraphQL 变量传递给 variables= 参数,在这些模板调用中使用它们
{% set user = graphql("""
query ($id: Int) {
users_row(id: $id) {
name
login
avatar_url
}
}
""", database="github", variables={"id": 9599})["users_row"] %}
<h1>Hello, {{ user.name }}h1>datasette-graphql 向 Datasette 添加了一个新的插件钩子,可用于向您的 GraphQL schema 添加自定义字段。
插件钩子如下所示
@hookimpl
def graphql_extra_fields(datasette, database):
"A list of (name, field_type) tuples to include in the GraphQL schema"您可以使用此钩子返回一个元组列表,描述应在您的 schema 中公开的额外字段。每个元组应包含一个命名新字段的字符串,以及一个指定 schema 并提供 resolver 函数的Graphene Field 对象。
此示例实现使用 pkg_resources 返回当前已安装的 Python 包列表
import graphene
from datasette import hookimpl
import pkg_resources
@hookimpl
def graphql_extra_fields():
class Package(graphene.ObjectType):
"An installed package"
name = graphene.String()
version = graphene.String()
def resolve_packages(root, info):
return [
{"name": d.project_name, "version": d.version}
for d in pkg_resources.working_set
]
return [
(
"packages",
graphene.Field(
graphene.List(Package),
description="List of installed packages",
resolver=resolve_packages,
),
),
]安装此插件后,可以使用以下 GraphQL 查询来检索已安装的包列表
{
packages {
name
version
}
}要在本地设置此插件,首先 checkout 代码。然后创建一个新的虚拟环境
cd datasette-graphql
python3 -mvenv venv
source venv/bin/activate
或者如果您正在使用 pipenv
pipenv shell
现在安装依赖项和测试
pip install -e '.[test]'
运行测试
pytest