使用 Datasette 学习 SQL
本教程是关于使用 Datasette 探索数据的教程的后续,它展示了如何使用 Datasette 来开始学习编写自己的自定义 SQL 查询。
我们将使用与该教程相同的示例数据库
该数据库包含关于美国总统、副总统和国会议员从 1789 年至今的信息。你可以按照先前的教程来熟悉这些数据。
SQL 和 SQLite
Datasette 是一种运行在 SQL 数据库之上的软件。有许多不同的 SQL 数据库系统,例如 MySQL、PostgreSQL、Microsoft SQL Server 和 Oracle。Datasette 使用的数据库叫做 SQLite。
你可能没有意识到,但你每天都在使用 SQLite:它内置于许多流行的应用程序中,包括 Google Chrome 和 Firefox,并且运行在笔记本电脑、iPhone、Android 手机以及各种其他小型设备上。
SQL 是 Structured Query Language(结构化查询语言)的缩写 - 它是一种用于对数据库运行查询的文本语言。每个数据库都实现了稍微不同的 SQL 方言 - 在本教程中,我将尽量使用 SQLite 方言中最有可能在其他数据库中也通用的子集。
查看和编辑 SQL
Datasette 中的每个表格页面 - 例如这个 - 都包含一个“查看和编辑 SQL”链接,它看起来像这样
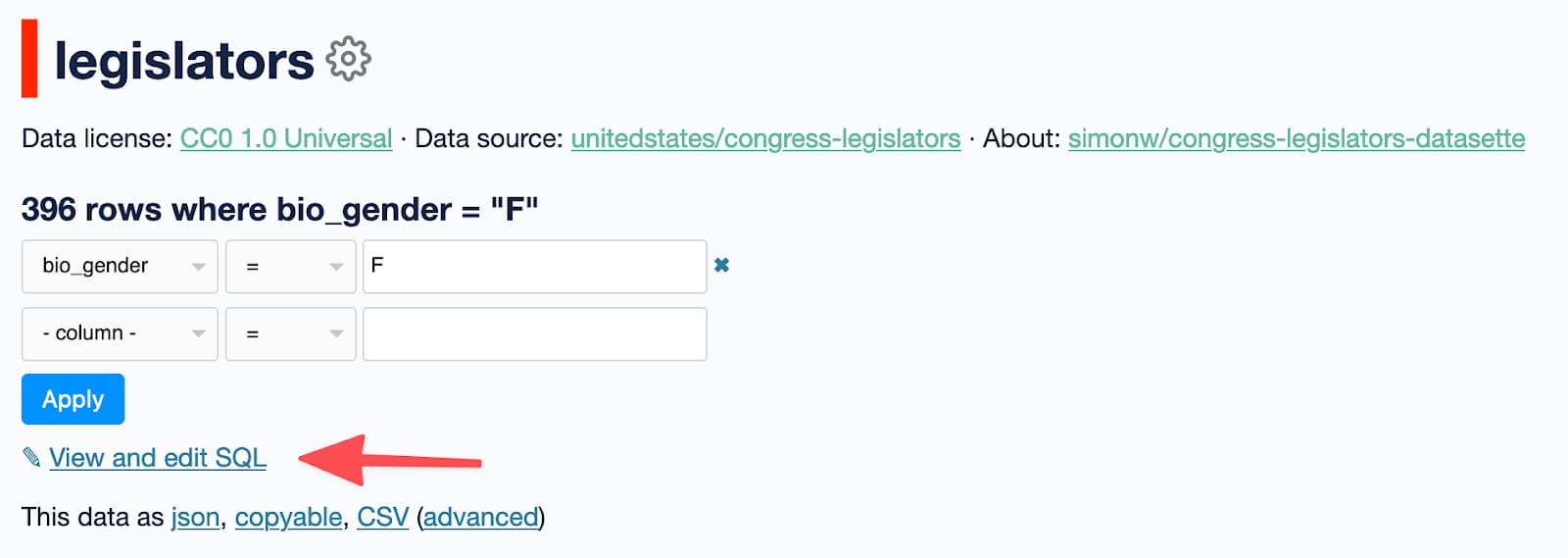
点击该链接即可查看当前页面使用的 SQL 查询 - 包括已应用的任何过滤器,在本例中是对 bio_gender = 'F' 的过滤。
然后你可以编辑该查询以实现其他功能!
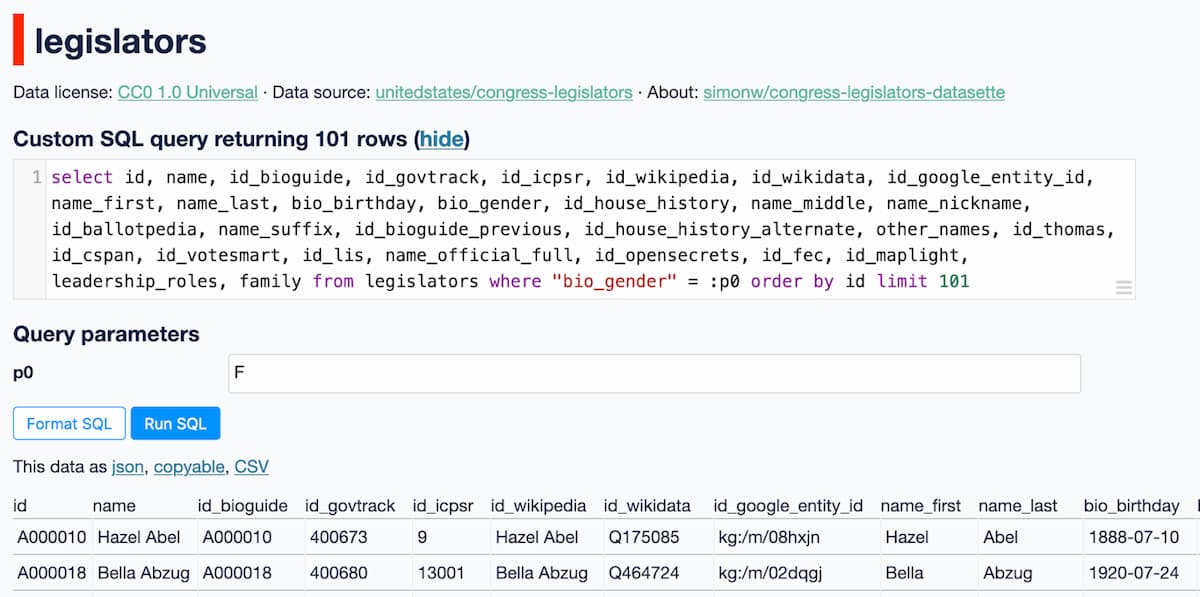
练习
从这个例子开始,然后
- 点击“格式化 SQL”以整理并使其更易于阅读和编辑
- 修改该查询以仅返回 id 和 name 列
- 使其按
name排序,而不是按id排序 - 将
p0的值改为M以返回男性议员而不是女性议员 - 尝试将列列表替换为
select * from- 这是所有列的快捷方式
基本 select 查询的结构
这是上述查询的格式化版本
select
id,
name,
id_bioguide,
id_govtrack,
id_icpsr,
id_wikipedia,
id_wikidata,
id_google_entity_id,
name_first,
name_last,
bio_birthday,
bio_gender,
id_house_history,
name_middle,
name_nickname,
id_ballotpedia,
name_suffix,
id_bioguide_previous,
id_house_history_alternate,
other_names,
id_thomas,
id_cspan,
id_votesmart,
id_lis,
name_official_full,
id_opensecrets,
id_fec,
id_maplight,
leadership_roles,
family
from
legislators
where
bio_gender = :p0
order by
id
limit
101
select
select 部分指定你想要返回哪些列。每个列名用逗号分隔 - 但是如果你在最后一个列名后面加上逗号,你将会得到一个错误消息。
near from: syntax error
from
from 部分指定应该从哪个表中选择记录 - 这里我们想要从 legislators 表中选择。
where
where 部分添加过滤条件。这些条件可以使用 and 结合,例如这个查询将只选择具有 Jr. 名字后缀的男性议员
where
bio_gender = 'M'
and name_suffix = 'Jr.'
此部分是可选的 - 如果你不包含 where 子句,你将获得表中的每一行。
order by
可选的 order by 子句指定你希望返回行的顺序。这会按名称字母顺序排列它们
order by
name
或者添加 desc 以反转顺序。这个查询返回最年轻的议员
select
*
from
legislators
order by
bio_birthday desc
limit
limit 101 子句将查询限制为仅返回前 101 条结果。在大多数 SQL 数据库中省略此子句将返回所有结果 - 但 Datasette 额外限制为 1,000 条(示例在此)以防止大型查询导致性能问题。
命名参数
在先前的教程中,我们使用了过滤器来列出发生在 19 世纪的总统任期,方法是过滤 start 列以字符串 18 开头且 type 列等于 prez 的行。
这是过滤后的表的示例。
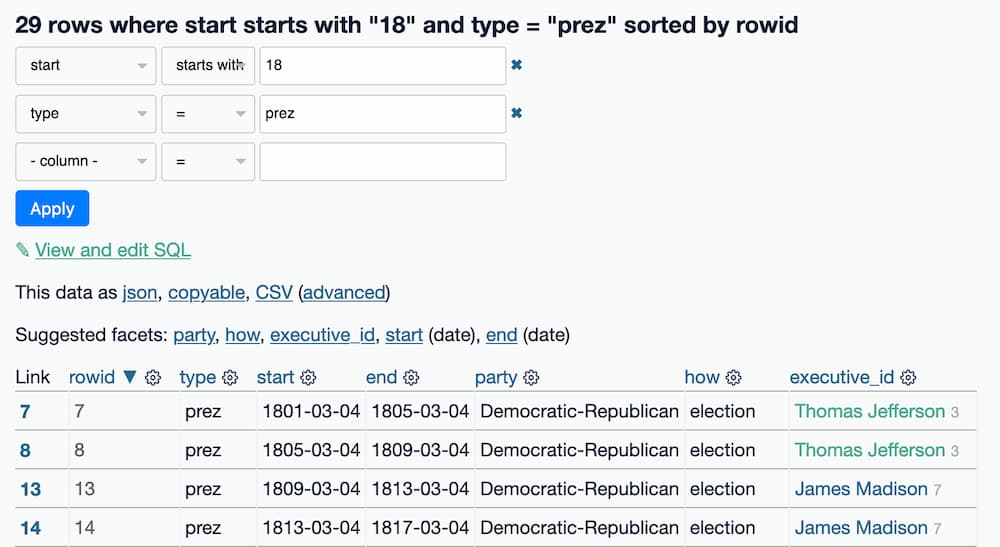
点击那个“查看和编辑 SQL”链接(然后点击“格式化 SQL”)会显示这个查询
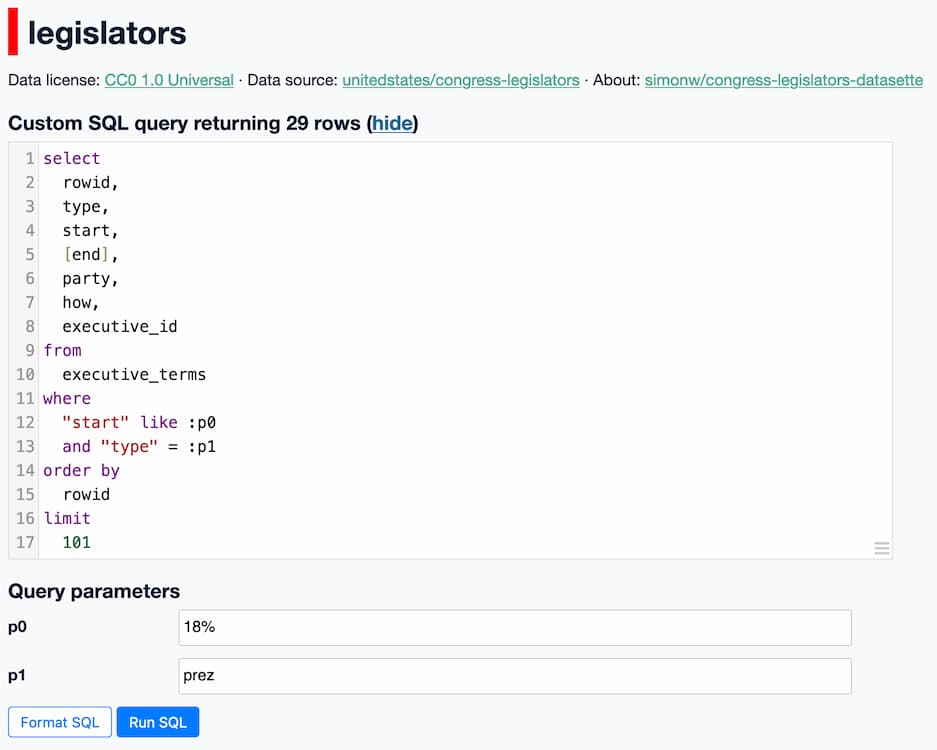
select
rowid,
type,
start,
end,
party,
how,
executive_id
from
executive_terms
where
start like :p0
and type= :p1
这里的 :p0 和 :p1 字段对应于“命名参数” - 它们提供了一种安全的方式将值传递给 SQL 查询,而无需担心SQL 注入。
这些字段名是从查询中提取的。如果你将 where 子句更改为这样
where
start like :century
and type = :type
那么将显示名为 century 和 type 的字段,而不是 p0 和 p1。
由于它们是表单字段,你也可以更改这些值。尝试将 prez 更改为 viceprez 以查看19 世纪的副总统任期。
如果你没有使用命名参数,查询的 where 子句可以改为这样
where
start like '18%'
and type = 'prez'
字符串值如 '18%' 和 'prez' 必须用单引号或双引号括起来(首选单引号),如果你没有使用 :p0 语法的话。
这里的列名周围的双引号是可选的 - 仅当列名可能与现有 SQL 关键字冲突(如 select 或 where),或者列名包含空格时才需要。所以下面的 where 子句工作方式相同
where
start like '18%'
and type = 'prez'
SQL LIKE 查询
为了查找 start 列以字符串 18 开头的行,我们使用这个 where 过滤器
where
start like '18%'
SQL like 运算符对字符串应用通配符 - % 表示“匹配任意字符”,而 _(下划线)表示“匹配单个字符”。
练习
- 使用 LIKE 过滤器查找发生在任意世纪 90 年代的总统任期 - 你需要同时使用 _ 和 %。(解答)
SQL JOIN
executive_terms 表有一个名为 executive_id 的列,它既显示数字 ID,也显示一个包含执行人姓名的链接

但是... 当你点击“查看和编辑 SQL”链接时,生成的查询只返回 ID,不返回名称。
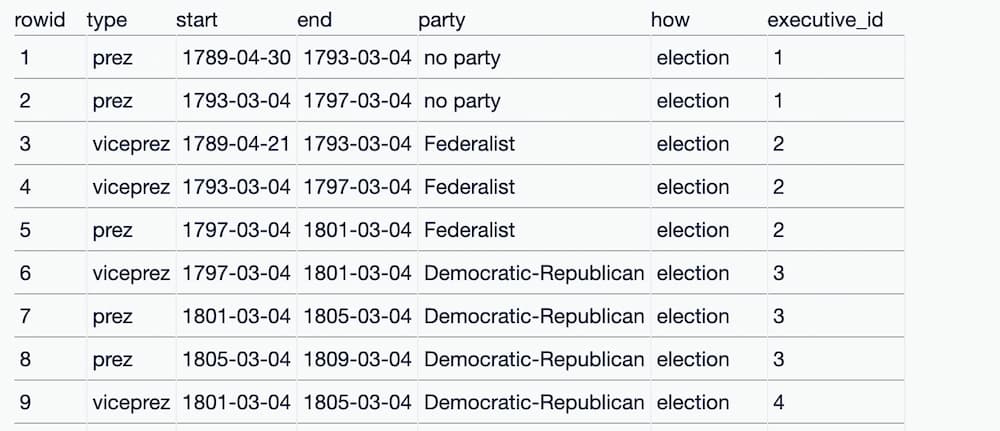
SQL join(联接)可用于组合来自多个表的数据。这是一个使用联接从 executives 表中获取名称的查询
select
executive_terms.type,
executive_terms.start,
executive_terms.end,
executive_terms.party,
executive_terms.how,
executives.name
from
executive_terms
join executives
on executive_terms.executive_id = executives.id
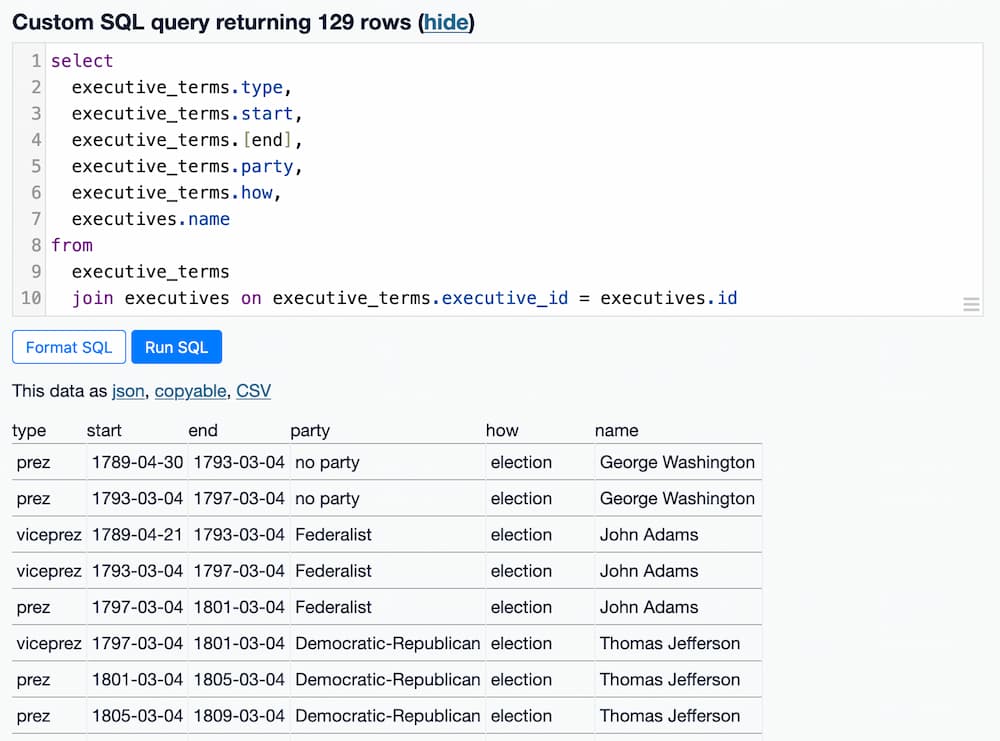
由于查询中涉及两个表,最好在 select 子句中包含明确的表名
select
executive_terms.type,
executive_terms.start,
executive_terms.end,
executive_terms.party,
executive_terms.how,
executives.name
如果一个列仅存在于两个表中的一个,你可以直接使用列名而不指定表,但这很快就会变得令人困惑,因此在执行联接时最好始终使用表名。
from 子句是定义 join 的地方。它描述了如何将两个表结合在一起
from
executive_terms
join executives
on executive_terms.executive_id = executives.id
我们正在将 executive_terms 表与 executives 表联接,利用了 executive_terms 表中的 executive_id 列包含了 executives 表中 id 列的值这一事实。
这就是为什么 IDs 和外键在 SQL 数据库中是重要的概念!
这种联接也称为“内联接”(inner join) - 它是最常用的联接。其他联接类型包括外联接(outer joins)和全联接(full joins),但这些超出了本教程的范围。
GROUP BY / COUNT
SQL 中一个常见的操作是询问列中最常见值的计数。
Datasette 在其分面功能中暴露了这种能力。在底层,该功能通过执行 group by / count 查询来实现。
以下查询回答了这个问题:哪个政党拥有最多的总统任期?
select
party,
count(*)
from
executive_terms
where
type = 'prez'
group by
party
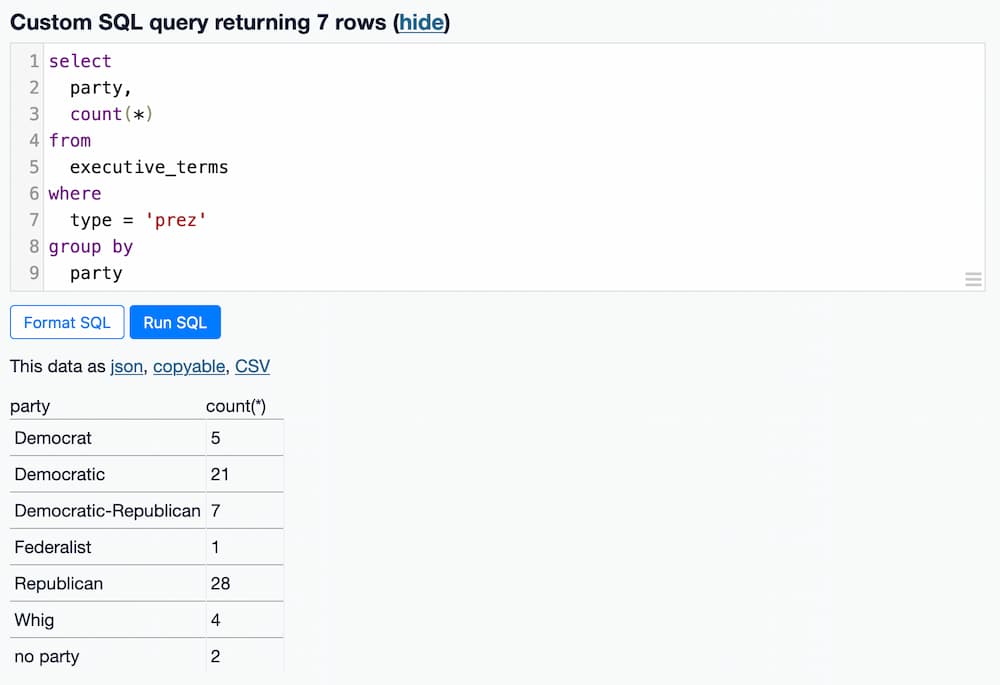
select 子句要求获取 party 列以及运行 count(*) 的结果。count() 是一个 SQL 聚合函数,它对一组结果进行操作。所以我们需要定义一个组。
末尾的 group by party 子句创建了这些组。两者的结合产生了期望的结果。
你可以在末尾添加这个 order by 子句,以查看从高到低排序的组
order by
count(*) desc
结果如下.
WHERE ... IN
SQL 查询可以通过多种有趣的方式嵌套在一起。
对于即席数据分析,最有用的模式之一是 where column in (select ...)。
让我们构建一个查询,看看所有既担任过总统又担任过副总统的人。
我们将从一个返回所有副总统姓名的查询开始。这需要与 executives 表进行联接,因为 executive_terms 表包含总统和副总统的任期信息,但不包含这些个人的姓名。
select
executives.name
from
executive_terms
join executives
on executive_terms.executive_id = executives.id
where
type = 'viceprez'
这个查询返回 61 行,其中包括一些担任多于一个副总统任期的个人的重复行。
如果需要,我们可以使用 select distinct 来删除这些重复项。
如果我们想看看所有既担任过总统又担任过副总统的人,我们可以像这样将两个查询结合起来
select
distinct executives.name
from
executive_terms
join executives
on executive_terms.executive_id = executives.id
where
type = 'prez'
and name in (
select
executives.name
from
executive_terms
join executives
on executive_terms.executive_id = executives.id
where
type = 'viceprez'
)
这个查询返回 15 个姓名,从约翰·亚当斯(John Adams)开始,到约瑟夫·拜登(Joseph Biden)结束。
⚠️ 此示例的早期版本暴露了一个细微的错误:在 executives 表中有两个同名的独立个体,乔治·布什(George Bush)和乔治·布什(George Bush)!因此,尽管查询看起来返回了正确的结果,但实际上包含一个错误。这是一个有用的演示,说明了尽可能使用唯一的、去重标识符的重要性,而不是假定姓名等信息是唯一的。
通用表表达式 (Common Table Expressions)
这是一种我每天都在使用的更高级的 SQL 技术:它可以使复杂的 SQL 查询更容易编写和理解。
通用表表达式(Common Table Expressions,简称 CTEs)允许你为 select 查询定义一个在当前查询持续期间有效的临时别名。然后你可以像对待普通表一样对待它。
这是一个创建了两个 CTE 的例子,一个叫做 presidents,一个叫做 vice_presidents,然后用它们来回答前面关于既担任过总统又担任过副总统的人的问题
with presidents as (
select
executives.name
from
executive_terms
join executives
on executive_terms.executive_id = executives.id
where
executive_terms.type = 'prez'
),
vice_presidents as (
select
executives.name
from
executive_terms
join executives
on executive_terms.executive_id = executives.id
where
executive_terms.type = 'viceprez'
)
select
distinct name
from
presidents
where name in vice_presidents
这两个 CTE 使用 with alias_name as (select ...), second_alias as (select ...) 来定义 - 然后在末尾添加返回最终结果的查询。
创建可书签的应用
由于 Datasette 上的每个页面都可以链接(参见分享链接),并且命名参数会自动向查询页面添加表单输入,因此你可以结合这两个功能来创建可书签的应用。
这对于与尚不了解 SQL 的人协作特别有用。你可以编写解决他们问题的 SQL 查询,添加他们可以自定义的参数,然后将整个自定义应用作为他们可以书签的链接发送给他们。
让我们创建一个应用,返回给定日期下的总统和副总统。
这是我们将使用的 SQL 查询
select
executives.name,
executive_terms.type,
executive_terms.start,
executive_terms.end,
executive_terms.party
from
executive_terms
join executives
on executive_terms.executive_id = executives.id
where
start <= :date
and end > :date
此查询接受一个 :date 参数,其格式应为 yyyy-mm-dd - 例如 2016-01-01。
它与 executives 表联接以获取他们的姓名,然后过滤出行,这些行的任期 start 小于或等于指定的日期,并且 end 大于该日期。我们在其中一个条件中使用 <= 以确保没有间隔或重叠。
如果我们在没有日期的情况下执行查询,它将返回 0 条结果,但会给我们一个表单字段来输入日期
输入一个日期 - 例如 2016-01-01 - 会返回该日期下的总统和副总统
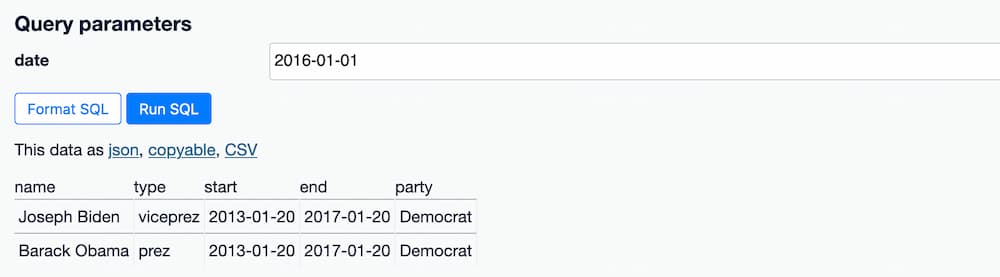
我们已经构建了一个应用!现在我们可以将此链接发送给任何人,他们都可以运行相同的查询。
页面顶部的 SQL 可能会让人感到有些畏惧。这就是“隐藏”链接的作用 - 点击它可以隐藏 SQL 查询,提供一个新的链接,你可以分享这个链接,用户无需滚动过 SQL 就能与查询互动。
最后一点说明:我们构建的应用也可以兼作 API。在 URL 的路径部分添加 .json,或者点击.json 链接,可以以 JSON 格式获取数据。在 URL 中添加 &_shape=array 可以获取更紧凑的 JSON 格式,非常适合与其他应用集成。
后续步骤
完全精通 SQL 需要多年时间。本教程尝试涵盖了 SQL 基础知识并介绍了一些更高级的技术来帮助管理大型查询,但还有很多东西需要学习。SQLite SELECT 文档提供了 SQLite 所理解的 SQL 的全面参考,但最好的学习方法是不断尝试针对不同数据进行新操作,并在过程中查找资料。